More than the risk of tech debt when relying on AI, I’ve been worried about a kind of knowledge debt. If you allow agents to pull your codebase ahead without your full attention, you’ll gradually understand less and less about it. I’ve been putting off this article for a couple of weeks, and in the meantime Addy Osmani published Comprehension Debt - the hidden cost of AI generated code:
Comprehension debt is the growing gap between how much code exists in your system and how much of it any human being genuinely understands.
As this gap accumulates, you lose the ability to diagnose issues and make decisions. And it can underly and intensify technical debt: if you don’t know how your codebase works, you don’t even know where the technical debt is.
Addy references an article by Margaret Storey, which refers to it as cognitive debt (matching the term used by a recent MIT study). She describes a student team that suffered from technical debt, but with a deeper underlying problem:
I saw this dynamic play out vividly in an entrepreneurship course I taught recently. Student teams were building software products over the semester, moving quickly to ship features and meet milestones. But by weeks 7 or 8, one team hit a wall. They could no longer make even simple changes without breaking something unexpected. When I met with them, the team initially blamed technical debt: messy code, poor architecture, hurried implementations. But as we dug deeper, the real problem emerged: no one on the team could explain why certain design decisions had been made or how different parts of the system were supposed to work together. The code might have been messy, but the bigger issue was that the theory of the system, their shared understanding, had fragmented or disappeared entirely. They had accumulated cognitive debt faster than technical debt, and it paralyzed them.
Technical debt is known; you deliberately implement something quickly knowing you’ll have to pay for it later. Cognitive debt produces unknown unknowns—you don’t know what sacrifices you’re making. As Addy puts it:
This is what makes comprehension debt more insidious than technical debt. Technical debt is usually a conscious tradeoff - you chose the shortcut, you know roughly where it lives, you can schedule the paydown. Comprehension debt accumulates invisibly, often without anyone making a deliberate decision to let it. It’s the aggregate of hundreds of reviews where the code looked fine and the tests were passing and there was another PR in the queue.
A lack of understanding of the current state of the project yields paralysis, not just because touching anything might break something but because it’s not clear how to build upon machinery that you don’t understand. Addy links out to Simon’s post on the topic:
I've been experimenting with prompting entire new features into existence without reviewing their implementations and, while it works surprisingly well, I've found myself getting lost in my own projects.
I no longer have a firm mental model of what they can do and how they work, which means each additional feature becomes harder to reason about, eventually leading me to lose the ability to make confident decisions about where to go next.
So, Addy writes, in a world where the cost of writing the code goes down, the value of comprehending the code goes up.
As AI volume goes up, the engineer who truly understands the system becomes more valuable, not less. The ability to look at a diff and immediately know which behaviors are load-bearing. To remember why that architectural decision got made under pressure eight months ago.
I would add that you need to understand the codebase to meaningfully maintain it: refactoring, restructuring, deduplicating, documenting the code (or adding context docs for AI). Without intentional maintenance, bad code compounds over time as AI struggles to find the information it needs and repeats its bad conventions. You need to understand your codebase to own it and keep it well-structured and easy to navigate for AI (and any other humans that still happen to be reading it).
These articles talk about the extreme case—what happens when cognitive debt gets completely out of hand. But I’ve found that it’s easy to get there quickly. If you use AI to generate the foundation of a project or a big feature, and don’t take the time to understand the moving parts, you’ll find that only AI can work on it, without your ability to meaningfully review the code going forward.
(Re)introducing CodeTour
You can commit to reading every line that it spits out, but as you let AI build more frequent and more complicated features, this becomes an increasingly tougher task. You don’t know what bits of code are the most important to read, and code isn’t linear: you don’t always know where to start or where to go next. An agent will give you a summary of its changes, but it usually won’t help you build a mental model of how the new code actually works. I wanted to give AI a better way to explain itself.
I recently discovered a VSCode extension created six years ago called CodeTour. It lets you make code annotations and organize them in a sequence, creating a guided “tour” through your codebase. From their README:
This is a step between code comments and internal documentation. When you’re trying to onboard someone to a new codebase, it helps to walk them through the code itself in a logical order. This gives code comments a narrative and puts internal documentation closer to the code. It also removes code comments from the code itself, making it more acceptable to provide longer comments and making it possible to have different tours commenting on the same line.
Code tours are saved and loaded through JSON files in your repo:
{ "$schema": "https://aka.ms/codetour-schema", "title": "Dummy Tour", "description": "A step-by-step walkthrough of how raw Obsidian markdown becomes rendered HTML. Covers content loading, pre-processing segmentation, the unified/remark/rehype pipeline, and each custom plugin.", "steps": [ { "file": "src/pages/blog.astro", "description": "This is my **blog** page", "line": 51 }, { "file": "src/pages/projects.astro", "description": "This is my **projects** page", "line": 26 } ]}Any plain text format is fodder for an LLM, so we can have AI create and edit code tours for us. And this has been my go-to tool to reduce cognitive debt over the past few weeks. Following Matt Pocock’s prd-to-plan skill, I have Claude Code build features one “phase” at a time. Then, after building a phase, I give it a prompt like
Write me a code tour explaining the changes you made, step by step, in a logical order.
Sometimes I’ll also mention specific parts of the code that I want elaboration on, or an assumption I want it to make about me as the learner. If I don’t have any tour files in the project yet, I link CodeTour’s documentation, though Claude can probably figure it out without it.
I find that this is incredibly helpful in structuring my code review. I usually do this within the same context in which the code was written, so it effectively allows the agent who wrote the code to tell you which lines are the most important. It saves me a lot of time and friction in a process that would otherwise be me looking through each change in the Git tab of my IDE and trying to makes sense of the web of dependencies.
At first, Claude would tend to clump a lot of information at the beginning of a long function, describing the whole thing in one step. So I added to CLAUDE.md
When writing tours, don't let a single step cover too much ground. Look for opportunities to break a step into substeps.
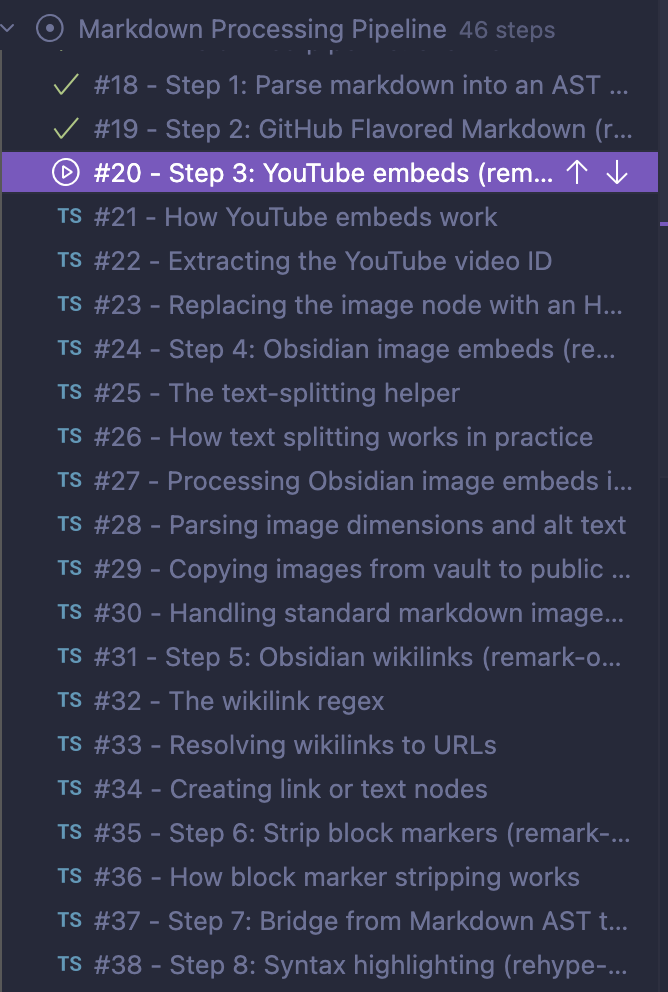
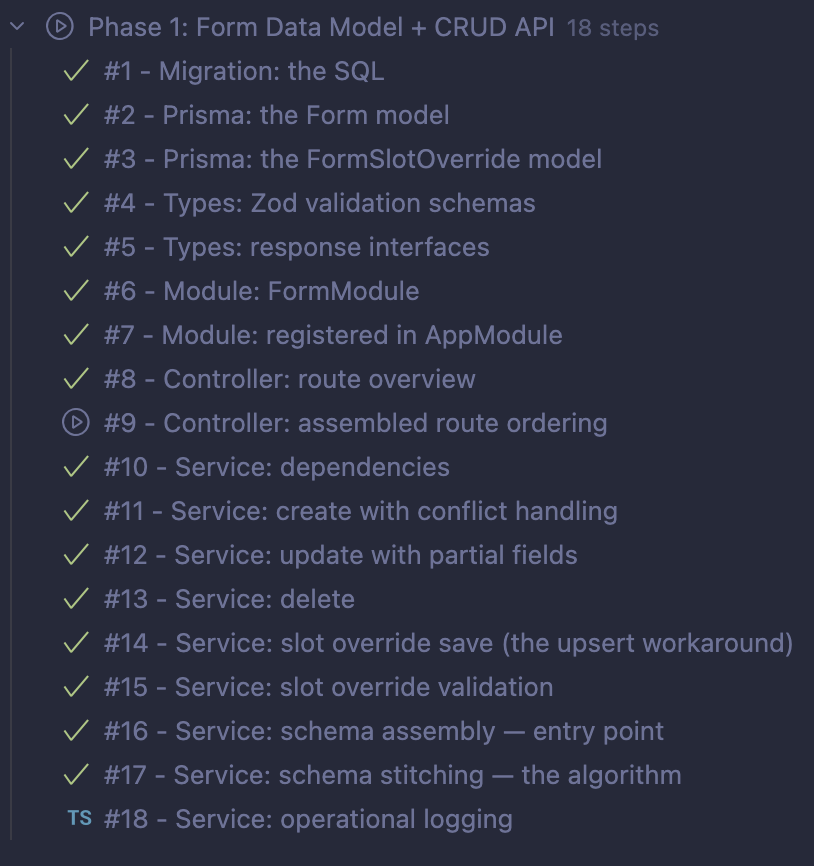
The generated tours are usually 10-20 steps long for a single phase of a feature. I’ve also used this to understand larger completed systems—below I have an example of a 46-step tour through the vibe-coded Obsidian markdown processing pipeline of this site.
Without additional prompting, it’s up to the agent to decide on the beats of this story. Sometimes it starts with a lay of the land of the problems we’re trying to solve or the state of things before the changes. (One tour I generated had the first three steps being “The problem”, “The constraint”, “The two part architecture”, all introducing the code in general.) Sometimes it will work you through a pipeline or request flow step by step, other times it goes layer by layer. It will often end with tests, and if it finds a change that doesn’t fit with the rest, it might tack it on as a “bonus” step.
| Examples: Step by step | Layer by layer |
|---|---|
 |
 |
While you’re reading the tour, you can use the tour step numbers as references when you talk to AI. They’re conversation starters in the sense that you can pick up where the AI left off explaining a piece of code. I’ll ask AI for more elaboration on something they said in the tour, and I’ll also often use a tour step to jumpstart new changes: “In #7, you said X does Y. X should actually do Z.” “The logic in #4 should be extracted out into its own function.”
Self-updating tours
When changes are made, I wanted the AI to immediately update the tour. So I had Claude write a check-tour-references hook to run on edit/write. This outputs the steps that live in files that have just been edited. This triggers an instruction in CLAUDE.md:
When you edit a file referenced by a
.tours/*.tourstep, thecheck-tour-referenceshook will flag affected steps with a code snippet showing what's currently at the referenced line. When this happens:
- Read the affected
.tourfile- Compare each flagged step's
lineanddescriptionagainst the code snippet in the hook output- Update any line numbers that shifted due to the edit
- If the code changed semantically (renames, refactors, deletions), update the step's
descriptionto match the new code
This solves a major problem with code tours in general, AI-generated or not. It’s hard to use them for documentation because they rely on precise line number references, which drift. That said, with a few tours in the project, this checking and adjustment process will add time to your AI edits. I only keep my tours around for the lifecycle of a PR, but if you wanted to use them for documentation, you might want to adjust the hook to run on commit.
Phase-specific tours might not be that useful to keep around, but full feature walk-through tours might be a helpful piece of documentation. I could also imagine a kind of ”collection” tour being useful in the long run, like a .code-search file that can track things that regex can’t and provide explanations for each one. Not just a list of all audit events, for example, but an in-depth explanation of the event and why we’re logging it. Totally automated, with the ability to add and edit manually.
Once I had Claude automatically updating the code tours, I had a problem—the extension wouldn’t actually update the tour until I manually reloaded it. So I had Claude clone the CodeTour repo, solve the problem, and rebuild the extension. I also had it replace the gutter icons with clickable CodeLens titles that bring up the tour step:
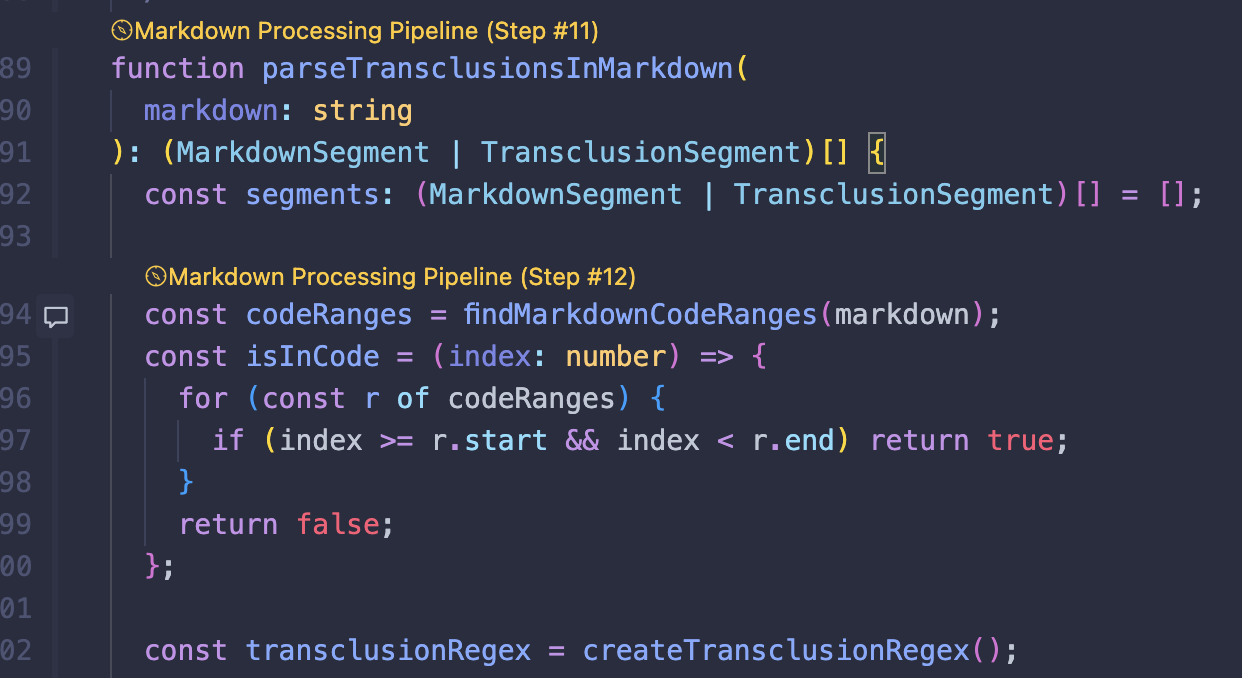
It’s never been easier to add a feature you want in someone else’s code. My (I want to say “our”) changes are on GitHub, and it’s no effort at all to add your own.
Can AI solve the problem it caused?
AI can’t do the work for you of reading and understanding the code—and really, interrogating it to make sure it’s doing what you want as well as possible. But it can help present the code it creates to make that job easier.
Writing your own documentation helps you build an understanding of your system and how it can improve, and I don’t think Code Tours replaces long-living, well-structured, comprehensive internal documentation. But it is another tool to help you build that understanding, and it’s a tool that helps bridge the gap between a rapidly growing code repo and your mental model trying to catch up to it.
I’ve found that I can notice when I’m taking cognitive shortcuts. When I ask the AI where something is in my codebase instead of working to remember it or search through the code, which would strengthen my memory. When I ask AI to make a small change and I don’t care to know where it made it. When I click through a code tour passively, rushing to get through it without analyzing the decisions that it’s documenting.
I have a vague idea of having AI quiz you about your code. I think that’s heading too far into the absurd, but the point is that, from Anki to Duolingo, we’ve used technology to force us to remember and understand things. And with AI, the scope of what AI can verify that we understand has expanded dramatically. AI doesn’t have to quiz us directly about our code—it can give us a writing prompt for a piece of internal documentation and then evaluate and correct it. This problem space of cognitive debt is crucial, it’s developing, and I want to be a part of solving it.